Es geschieht im Stillen, ohne Eilmeldungen oder öffentliche Erklärungen. Mächtige Kräfte arbeiten daran, das Internet zu säubern, Aufzeichnungen zu löschen, den Zugriff auf archivierte Inhalte zu sperren und unser kollektives digitales Gedächtnis neu zu schreiben.
Wenn sie Erfolg haben, werden die Konsequenzen weitreichende Auswirkungen haben, die alles von politischer Transparenz bis hin zu historischer Genauigkeit beeinflussen. Doch die meisten Menschen verschließen die Augen und lassen alles geschehen, obwohl wir fragen sollten, wer hinter dieser digitalen Auslöschung steckt – und warum sie so verzweifelt versuchen, die Wahrheit zu begraben und ihre Spuren zu verwischen.
Zensur ist mittlerweile so weit verbreitet, dass sie fast schon normal ist. Trotz laufender Gerichtsverfahren und größerer öffentlicher Aufmerksamkeit üben soziale Medien im Jahr 2024 mehr Zensur aus als je zuvor. Inhaltsersteller wissen, was sofort gelöscht wird, und sie diskutieren untereinander über Inhalte in Grauzonen. Einige, wie The People’s Voice , haben YouTube zugunsten von Rumble komplett aufgegeben und damit Einnahmen geopfert, nur um sicherzustellen, dass ihre Inhalte überleben und ein Publikum erreichen können.
Brownstone.org berichtet : Es geht nicht immer darum, ob zensiert wird oder nicht. Die heutigen Algorithmen beinhalten eine Reihe von Tools, die die Such- und Auffindbarkeit beeinflussen. So erreichte das Interview von Joe Rogan mit Donald Trump erstaunliche 34 Millionen Aufrufe, bevor YouTube und Google ihre Suchmaschinen so optimierten, dass es schwer zu finden war, und es sogar aufgrund einer technischen Störung für viele Leute nicht mehr zu sehen war. Angesichts dieser Situation ging Rogan auf die Plattform X, um alle drei Stunden zu posten.
Für die alternativen Medien ist es mittlerweile Teil ihres Geschäftsmodells geworden, sich in diesem Dickicht der Zensur und Quasi-Zensur zurechtzufinden.
Dies sind nur die Schlagzeilen. Hinter den Schlagzeilen finden technische Ereignisse statt, die die Fähigkeit eines jeden Historikers, auch nur zurückzublicken und zu sagen, was passiert, grundlegend beeinträchtigen. Unglaublicherweise hat der seit 1994 bestehende Dienst Archive.org aufgehört, Bilder von Inhalten auf allen Plattformen aufzunehmen. Zum ersten Mal seit 30 Jahren ist ein langer Zeitraum vergangen – seit dem 8. bis 10. Oktober – seit dieser Dienst das Leben des Internets in Echtzeit aufgezeichnet hat.
Zum Zeitpunkt des Schreibens dieses Artikels haben wir keine Möglichkeit, Inhalte zu überprüfen, die in den drei Oktoberwochen vor den Tagen der umstrittensten und folgenreichsten Wahl unseres Lebens gepostet wurden. Entscheidend ist, dass es hier nicht um Parteilichkeit oder ideologische Diskriminierung geht. Keine Website im Internet wird auf eine Weise archiviert, die den Benutzern zur Verfügung steht. Tatsächlich ist der gesamte Speicher unseres wichtigsten Informationssystems im Moment nur ein großes schwarzes Loch.
Die Probleme mit Archive.org begannen am 8. Oktober 2024, als der Dienst plötzlich von einem massiven Denial-of-Service-Angriff (DDOS) getroffen wurde, der den Dienst nicht nur lahmlegte, sondern auch zu einem Ausmaß an Fehlern führte, das ihn fast vollständig lahmlegte. Archive.org arbeitete rund um die Uhr und kehrte als schreibgeschützter Dienst in den Zustand zurück, in dem er heute ist. Sie können jedoch nur Inhalte lesen, die vor dem Angriff gepostet wurden. Der Dienst hat die öffentliche Anzeige von Spiegelungen von Websites im Internet noch nicht wieder aufgenommen.
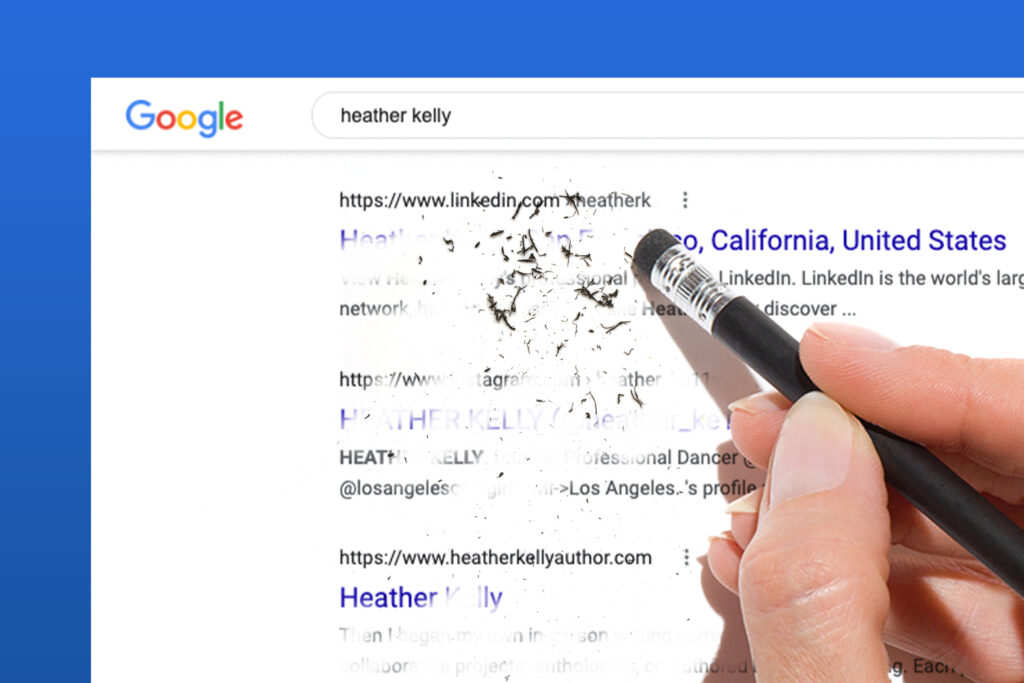
Mit anderen Worten: Die einzige Quelle im gesamten World Wide Web, die Inhalte in Echtzeit widerspiegelt, wurde deaktiviert. Zum ersten Mal seit der Erfindung des Webbrowsers selbst wurde den Forschern die Möglichkeit genommen, vergangene mit zukünftigen Inhalten zu vergleichen, eine Funktion, die für Forscher, die sich mit Regierungs- und Unternehmensaktivitäten befassen, ein wesentlicher Bestandteil ist.
Mithilfe dieses Dienstes konnten die Brownstone-Forscher beispielsweise genau herausfinden, was die CDC über Plexiglas, Filtersysteme, Briefwahlen und Mietmoratorien gesagt hatte. Diese Inhalte wurden später alle aus dem Live-Internet gelöscht, sodass der Zugriff auf Archivkopien die einzige Möglichkeit war, herauszufinden und zu überprüfen, was wahr war. Dasselbe galt für die Weltgesundheitsorganisation und ihre Verunglimpfung der natürlichen Immunität, die später geändert wurde. Wir konnten die wechselnden Definitionen nur dank dieses Tools dokumentieren, das jetzt deaktiviert ist.
Das bedeutet Folgendes: Jede Website kann heute alles posten und es morgen wieder entfernen, ohne dass etwas davon protokolliert wird, es sei denn, ein Benutzer macht zufällig irgendwo einen Screenshot. Und selbst dann gibt es keine Möglichkeit, die Echtheit zu überprüfen. Der Standardansatz, um herauszufinden, wer was wann gesagt hat, ist damit hinfällig. Das heißt, das gesamte Internet wird bereits in Echtzeit zensiert, sodass in diesen entscheidenden Wochen, in denen große Teile der Öffentlichkeit mit Fälschungen rechnen, jeder in der Informationsbranche mit allem davonkommen kann, ohne erwischt zu werden.
Wir wissen, was Sie denken. Dieser DDOS-Angriff war sicher kein Zufall. Der Zeitpunkt war einfach zu perfekt. Und vielleicht stimmt das auch. Wir wissen es einfach nicht. Vermutet Archive.org etwas in dieser Richtung? Hier ist, was sie sagen :
Letzte Woche wurde neben einem DDOS-Angriff und der Offenlegung von E-Mail-Adressen und verschlüsselten Passwörtern von Benutzern auch das JavaScript der Website des Internetarchivs beschädigt, was uns dazu veranlasste, die Website herunterzufahren, um unsere Sicherheit zu verbessern. Die gespeicherten Daten des Internetarchivs sind sicher und wir arbeiten daran, die Dienste sicher wieder aufzunehmen. Diese neue Realität erfordert erhöhte Aufmerksamkeit für die Cybersicherheit und wir reagieren darauf. Wir entschuldigen uns für die Auswirkungen der Nichtverfügbarkeit dieser Bibliotheksdienste.
Deep State? Wie bei all diesen Dingen gibt es keine Möglichkeit, das herauszufinden, aber die Bemühungen, die Fähigkeit des Internets, eine verifizierte Historie zu haben, zu zerstören, passen perfekt in das Stakeholder-Modell der Informationsverteilung, das auf globaler Ebene eindeutig Priorität hat. Die Erklärung zur Zukunft des Internets macht das sehr deutlich: Das Internet sollte „durch den Multi-Stakeholder-Ansatz geregelt werden, bei dem Regierungen und zuständige Behörden mit Akademikern, der Zivilgesellschaft, dem privaten Sektor, der technischen Community und anderen zusammenarbeiten“. Alle diese Stakeholder profitieren von der Möglichkeit, online zu agieren, ohne Spuren zu hinterlassen.
Ein Bibliothekar von Archive.org hat geschrieben : „Während die Wayback Machine im Nur-Lese-Modus war, wurden das Web-Crawling und die Archivierung fortgesetzt. Diese Materialien werden über die Wayback Machine verfügbar sein, sobald die Dienste gesichert sind.“
Wann? Wir wissen es nicht. Vor der Wahl? In fünf Jahren? Es mag technische Gründe geben, aber es könnte sein, dass, wenn das Web-Crawling hinter den Kulissen weitergeht, wie es die Notiz nahelegt, auch das jetzt nur noch im Lesemodus verfügbar sein könnte. Das ist aber nicht der Fall.
Beunruhigenderweise findet diese Löschung des Internetgedächtnisses an mehreren Stellen statt. Viele Jahre lang bot Google eine zwischengespeicherte Version des gesuchten Links direkt unter der Live-Version an. Sie verfügen jetzt über genügend Serverplatz, um dies zu ermöglichen, aber nein: Dieser Dienst ist jetzt vollständig verschwunden. Tatsächlich wurde der Google-Cache-Dienst offiziell nur eine oder zwei Wochen vor dem Absturz von Archive.org, Ende September 2024, eingestellt .
Somit verschwanden die beiden verfügbaren Tools zum Durchsuchen zwischengespeicherter Seiten im Internet innerhalb weniger Wochen nacheinander und innerhalb weniger Wochen nach den Wahlen vom 5. November.
Auch andere beunruhigende Trends verwandeln Internetsuchergebnisse zunehmend in KI-gesteuerte Listen von vom Establishment abgesegneten Narrativen. Früher war es im Web Standard, dass die Rangfolge der Suchergebnisse durch Nutzerverhalten, Links, Zitate usw. bestimmt wurde. Dabei handelte es sich mehr oder weniger um organische Metriken, die auf einer Aggregation von Daten basierten, die anzeigten, wie nützlich ein Suchergebnis für Internetnutzer war. Vereinfacht ausgedrückt: Je nützlicher die Leute ein Suchergebnis fanden, desto höher wurde es eingestuft. Google verwendet heute ganz andere Metriken zur Rangfolge der Suchergebnisse, darunter das, was es als „vertrauenswürdige Quellen“ betrachtet, und andere undurchsichtige, subjektive Festlegungen.
Außerdem gibt es den am weitesten verbreiteten Dienst, der einst Websites nach Traffic bewertete, nicht mehr. Dieser Dienst hieß Alexa. Das Unternehmen, das ihn entwickelte, war unabhängig. Dann wurde er eines Tages im Jahr 1999 von Amazon gekauft. Das schien ermutigend, denn Amazon war wohlhabend. Die Übernahme schien das Tool zu kodifizieren, das jeder als eine Art Statusmaßstab im Web verwendete. Damals war es üblich, irgendwo im Web einen Artikel zu bemerken und ihn dann bei Alexa nachzuschlagen, um seine Reichweite zu sehen. Wenn er wichtig war, wurde er bemerkt, aber wenn nicht, interessierte es niemanden besonders.
So hat eine ganze Generation von Webtechnikern gearbeitet. Das System hat so gut funktioniert, wie man es sich nur wünschen konnte.
Dann, im Jahr 2014, Jahre nach der Übernahme des Ranking-Dienstes Alexa, tat Amazon etwas Seltsames. Es brachte seinen Heimassistenten (und Überwachungsgerät) unter demselben Namen heraus. Plötzlich hatte jeder ihn zu Hause und konnte alles herausfinden, indem er „Hey Alexa“ sagte. Es schien etwas seltsam, dass Amazon sein neues Produkt nach einem nicht verwandten Unternehmen benannte, das es Jahre zuvor übernommen hatte. Zweifellos gab es eine gewisse Verwirrung aufgrund der Namensüberschneidung.
Und so geschah es dann. Im Jahr 2022 nahm Amazon das Web-Ranking-Tool aktiv vom Netz. Es wurde nicht verkauft. Die Preise wurden nicht erhöht. Es wurde nichts damit gemacht. Es wurde plötzlich komplett dunkel.
Niemand konnte herausfinden, warum. Es war der Industriestandard und plötzlich war es weg. Nicht verkauft, einfach weggeblasen. Niemand konnte mehr die verkehrsbasierten Website-Rankings von irgendetwas herausfinden, ohne sehr hohe Preise für schwer zu verwendende proprietäre Produkte zu zahlen.
Alle diese Datenpunkte, die einzeln betrachtet vielleicht nichts miteinander zu tun haben, sind tatsächlich Teil einer langen Entwicklung, die unsere Informationslandschaft in eine nicht wiederzuerkennende Richtung verschoben hat. Die Covid-Ereignisse von 2020 bis 2023 mit ihren massiven weltweiten Zensur- und Propagandabemühungen haben diese Trends stark beschleunigt.
Man fragt sich, ob sich noch irgendjemand daran erinnern wird, wie es einmal war. Das Hacken und Beeinträchtigen von Archive.org unterstreicht diesen Punkt: Es wird keine Erinnerung mehr geben.
Zum Zeitpunkt des Schreibens dieses Artikels wurden noch nicht einmal drei Wochen Webinhalte archiviert. Was uns fehlt und was sich geändert hat, kann jeder nur raten. Und wir haben keine Ahnung, wann der Dienst wieder verfügbar sein wird. Es ist durchaus möglich, dass er nicht wieder verfügbar sein wird und dass die einzige wirkliche Geschichte, auf die wir zurückgreifen können, die vor dem 8. Oktober 2024 liegt, dem Datum, an dem sich alles änderte.
Das Internet wurde als freies und demokratisch konzipiertes System gegründet. Um diese Vision wiederherzustellen, bedarf es herkulischer Anstrengungen, denn sie wird rasch durch etwas anderes ersetzt.